Introduction
If you’re a software developer, or even a product person, you’ve likely encountered the challenge of code refactoring. Over years of building software, I’ve developed a new way of thinking about this process, especially when dealing with large, complex codebases. What I’m sharing here is my own approach, a pattern, a mindset, and a practice that has consistently helped me navigate some of the trickiest code refactors.
I call this the Backward Refactoring, and I’ve introduced and refined it through my experiences and shared these insights on my website. This article continues that conversation, unpacking the pattern in detail for anyone facing big, daunting refactoring efforts.
Every refactoring journey can feel like traversing a dangerous mountain path, whether it’s a minor tweak or a massive overhaul. Big, planned refactors are particularly daunting. They demand more tools, precision, and patience than building something fresh from scratch. Improving existing code is its own unique challenge and requires special approaches, strategies, and care. This often leads to the question: Is refactoring always this difficult?
Imagine trying to replace the engine of an airplane while it’s still soaring thousands of feet in the air. The stakes are high, the risks are real, and the path forward can seem almost impossible. This is what refactoring a sprawling, tangled codebase feels like. It’s a challenge that brings to mind the ancient paradox of the Ship of Theseus:
“If you replace every single part of a ship, one by one, is it still the same ship?”
The Ship of Theseus Paradox
This question captures the core philosophical dilemma of a large refactor. A minor tweak is just replacing a single rotten plank, which doesn’t challenge the ship’s identity. But a massive overhaul, where you’ve replaced every single component, leaves you with a brand new ship that still carries the old name. The code is the same, but different; it’s a new machine built on the foundation of the old, and navigating that transformation is the trickiest part.
What if you started a refactor with the end in mind? Instead of blindly pushing forward, you use your tests and compiler as a map, which guides you through each step. That’s the core of Backward Refactoring. It’s a way to tackle big refactors by first imagining what the perfect code looks like. From there, you make small, safe changes, letting your tools tell you what to do next. This turns a huge, overwhelming project into a clear path you can follow one step at a time.
This series will walk through this approach step-by-step, from mindset to practical techniques and real-world examples. This first article focuses on the mindset necessary to embark on big refactoring journeys.
I already used the backward stepping approach in my EDD approach.
Why Is Refactoring So Hard?
Imagine you’re tasked with building a garden. If you start with a blank plot of land, you can design clear pathways, plant beds, and water systems exactly as you want. This is like developing a new feature from scratch, your blueprint is clean, your vision clear.
Now, imagine instead that you’re sent into a dense, overgrown forest full of winding trails, thorny bushes, and hidden roots. You need to clear a path while avoiding damage to the rare flowers beneath. This is what refactoring feels like when you work with existing code.
When you start implementing a feature from scratch, it’s like having or drawing a blank blueprint to build a garden. You can design it exactly as you want, with clear paths and a predictable outcome. That map in your hands acts as the end desired goal you’re going to reach. But when you start with refactoring, it’s like you’re already in a dense forest. Your map isn’t blank; it’s filled with the existing state, the winding trails, the overgrown brush, and the hidden obstacles. Your journey doesn’t just include the destination; it’s also defined by the terrain you’re currently in. This is what makes it so challenging.
Every line of legacy code is part of the terrain you must navigate. You cannot simply erase it; you must carefully replace and reshape it without breaking the system. This complexity makes refactoring, especially large, scheduled efforts, more challenging than initial development.
“Change is the law of life. And those who look only to the past or present are certain to miss the future.”
John F. Kennedy
Refactoring as a Goal vs. Refactoring as a Road Flatter
It’s crucial to distinguish between these two types of refactoring. When you refactor with the sole purpose of improving the existing code, your journey has one clear goal: the refactoring itself. Once the code is cleaner and more maintainable, your work is done.
However, when your goal is to implement a new feature and you have to refactor first to make that possible, the journey feels different. Refactoring isn’t the end goal; it’s a necessary step to reach another goal. It can feel like you have two separate, equally important goals, and this can be overwhelming. This is why I treat even this type of refactoring as a distinct, self-contained phase. It’s a way of flattening the road so I can later drive smoothly, rather than trying to flatten the road while I’m already on it.
“If you can’t measure it, you can’t improve it.”
Peter Drucker
This classic management quote perfectly encapsulates the need for a specific, measurable goal to guide and validate a refactoring effort.
Always Begin Your Refactoring Journey with a Quantitative Goal
I always separate the journey of refactoring from the journey of implementing a feature or fixing a bug. Even if the refactoring is just a prerequisite for a new feature, I treat it as its own project.
It’s like deciding to clean and organize a garage before you start a new woodworking project. The cleaning isn’t the project itself, but it’s a necessary step. My quantitative goal might be something specific like “reduce the Cyclomatic complexity of the OrderProcessor class from 25 to under 10” or “decouple the UserAuthentication module so it no longer depends on the EmailService.” Having a concrete, measurable goal gives me a clear finish line and helps me stay focused and accountable.
The Ship of Theseus: A Metaphor for Code Refactoring
“Refactoring is a controlled technique for improving the design of an existing code base. Its essence is applying a series of small behavior-preserving transformations, each of which ‘too small to be worth doing’.”
Marin Fowler
Philosophers have long debated the identity of the Ship of Theseus. If you replace every plank, nail, and sail over time, is it still the same ship? The paradox poses a profound question: when does a series of changes transform something from the original into something new?
This metaphor perfectly captures the dilemma in code refactoring. As you rewrite your code piece by piece, when does the codebase become “new”? How do you ensure you don’t lose the essence, the expected behavior and business logic, while improving the structure?
Thinking about this paradox helps ground us in two truths:
- Refactoring is about evolution, not replacement. The goal is continuous improvement, not sudden replacement.
- Preserving identity means preserving behavior. Even if the internal parts change, the system’s observable behavior must remain stable.
To understand a codebase’s identity, we must first tell its story. Imagine a critical piece of your e-commerce platform. Its sole purpose, its fundamental identity, is to process customer orders. It’s the beating heart of your revenue stream. But what about its history?
It didn’t start as a complex system; it was likely a small, elegant script written years ago by an ambitious engineer. As the business grew, new requirements emerged. A different developer added a quick-fix for a new payment method. Another patched in logic for a seasonal sale. Each change, each new piece of functionality, was a new plank added to the original ship. This code doesn’t exist in a vacuum; it’s deeply connected to other parts of the system, the inventory management, user authentication, and the shipping APIs. It’s not just a function; it’s a central hub, and its hidden complexities affect every other service it interacts with. Understanding its full history and context is paramount.
The Identity of a Codebase
To truly understand a codebase’s identity, we must document its story in a structured manner. This process is the first step in refactoring, especially when the code’s original purpose is unclear. By laying out its essential characteristics, we can begin to act as code archaeologists, uncovering its true function and history.
When you start implementing a feature from scratch, it’s like having or drawing a blank blueprint to build a garden. You can design it exactly as you want, with clear paths and a predictable outcome. That map in your hands acts as the end desired goal you’re going to reach. But when you start with refactoring, it’s like you’re already in a dense forest. Your map isn’t blank; it’s filled with the existing state, the winding trails, the overgrown brush, and the hidden obstacles. Your journey doesn’t just include the destination; it’s also defined by the terrain you’re currently in. This is what makes it so challenging.
This structured analysis serves as the “as-is” map of the code, a crucial first step before we can draw the “to-be” map for our refactoring journey. This process forces us to confront the current state head-on, ensuring our strategy is based on reality, not assumptions.
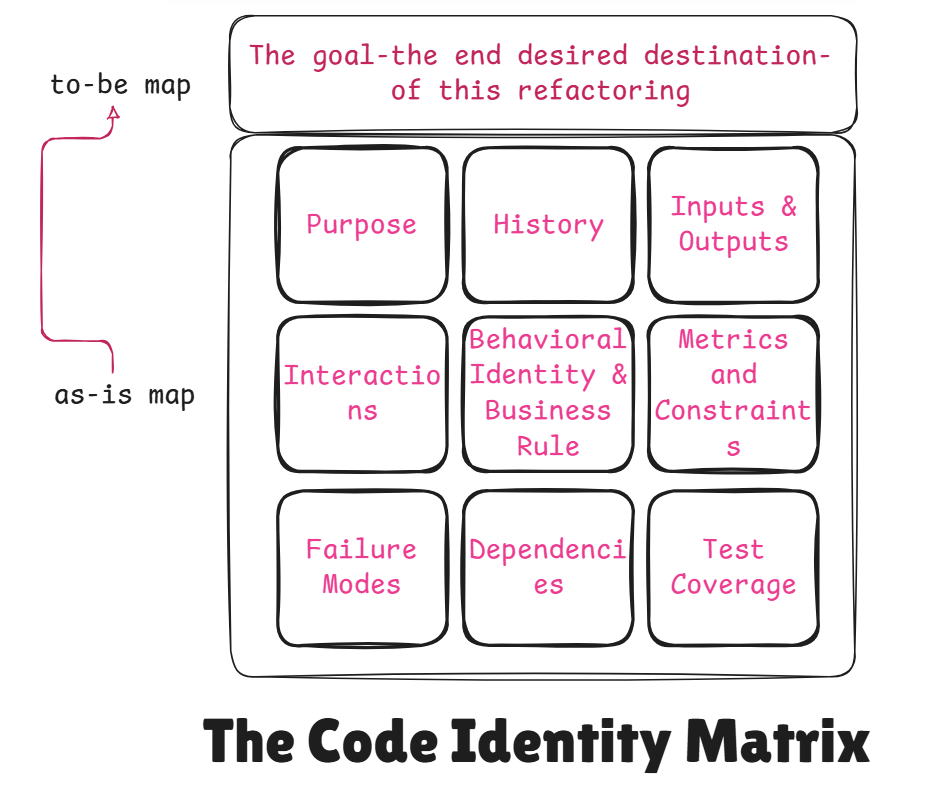
The Code Identity Matrix
To get a complete picture, we need to document the following aspects of the code:
1. Purpose: The “Why” of the Code This section defines the core reason for the code’s existence. What fundamental business function does it serve?
- Core Function: Ex: This code is the beating heart of the e-commerce platform. Its sole purpose is to process customer orders, ensuring every item is accounted for and every transaction is completed successfully.
- Business Goal: Ex: To manage the entire order lifecycle from initial placement to final confirmation, thereby securing the company’s revenue stream.
2. History: The Narrative of its Evolution This section tells the story of how the code came to be in its current state, detailing its growth and the accumulation of technical debt.
- Origin: Ex: The code started as a small, elegant script written years ago by an ambitious engineer!
- Growth: Ex: Over time, it was patched and expanded by different developers with quick fixes for new requirements (e.g., a new payment method, a seasonal sale logic). Each of these changes added a new “plank” to the original “ship” altering its structure.
- Current State: Ex: The code is now a complex system with hidden intricacies, a result of its long and undocumented history.
3. Sample Inputs and Outputs This provides concrete examples of how the code behaves from an external perspective, preserving its observable behavior.
- Sample Input: Ex: An order object in JSON format containing details such as customer_id, a list of items (with product_id and quantity), shipping_address, and payment_details.
- Sample Output: Ex: A processed order status with a unique order_id, a transaction_id from the payment gateway, and a status (e.g., “processing”, “fulfilled” or “payment_failed”).
4. Interactions with Other Systems This section maps the code’s role within the larger ecosystem, identifying its dependencies and connections.
- Central Hub: Ex: The code is not a standalone function; it acts as a central hub for the e-commerce platform.
- Dependencies: Ex: It communicates with several other services, including the Inventory Management System (to update stock levels), the User Authentication System (to verify customer identity), and the Shipping API (to arrange delivery).
- Impact: Ex: Any change to this code has a direct impact on these interconnected systems, making a full understanding of its role paramount.
5. Behavioral Identity & Business Rules Beyond just sample inputs and outputs, it’s essential to document the specific business rules and logical flow that the code enforces. This includes a catalog of all the different scenarios, exceptions, and edge cases the code handles. For example, how does the order processor handle a user’s coupon code? What about out-of-stock items or fraud detection? Documenting these behaviors ensures that every subtle piece of business logic is preserved during the refactor.
6. Performance Metrics & Constraints The “as-is” analysis must include a quantitative measure of the code’s performance. Refactoring is often driven by a need for speed or efficiency. We need to document:
- Latency: How long does it take for a request to be processed?
- Resource Usage: What is the average CPU, memory, and disk usage of the module?
- Scalability: How does the code behave under high load? Does its performance degrade significantly?
7. Failure Modes & Error Handling A critical part of a code’s identity is how it behaves when things go wrong. Documenting the current state of error handling is paramount. This includes:
- Error Types: What specific errors can the module return (e.g., invalid_payment, out_of_stock, user_not_found)?
- Failure Behavior: Does the code fail gracefully, or does it crash the entire system?
- Recovery: How does the system recover from an error, and what actions (e.g., logging, retries) are performed?
8. Dependencies Your analysis mentions interactions with other systems, but it’s also important to map the code’s dependencies. This means identifying which specific functions, classes, or data structures within the code itself are tightly coupled with the module you are analyzing. A visual diagram, such as a dependency graph, would be an invaluable addition to the matrix.
9. Test Coverage For any refactoring journey, the level of existing test coverage is the most important indicator of risk. This section should document the current percentage of code covered by automated tests. A low number here highlights the most significant immediate risk and underscores the necessity of building a robust test suite as the first major step in your refactoring roadmap.
This structured analysis serves as the “archaeological dig” you mentioned, allowing a developer to rediscover the code’s true identity before attempting any refactoring.
The Lost Identity
I know, I know, for some legacy code, no one in the organization, not even the person in the last chair in the basement wearing very big glasses, knows for sure the essential purpose, the essence, and the identity of existing code. This is where the Ship of Theseus metaphor takes on its most challenging form.
When the original purpose of a piece of code is lost, you’re not just trying to replace a plank on the ship; you’re doing it without knowing if that plank is part of the mast, the rudder, or the hull. Without a clear understanding of its identity and its role in the larger system, every refactoring decision is a guess. The first step, in this case, isn’t to change the code at all; it’s to act as a code archaeologist, to excavate and rediscover its original purpose. In the next parts, I’ll talk about these scenarios.
The Goal of the Refactoring: The “To-Be” Map
This final step transforms your understanding of the past into a concrete vision for the future. The connection between the “as-is” analysis and this goal is critical: the “to-be” map directly addresses the problems and challenges you uncovered in your matrix.
This is where the Ship of Theseus paradox becomes your guiding principle. Your “to-be” goal isn’t to build a brand new, unrelated ship. It’s to meticulously replace every worn-out plank, frayed rope, and broken component while preserving the ship’s core identity. The goal is to ensure the final product, despite being made of entirely new parts, is still recognizably the same functioning vessel.
The mindset here is not about building new code blindly. It’s a strategic, design-first approach where your goals are specific, measurable, and tied to desired business outcomes. This is how you transform a vague idea of “fixing the code” into a precise, actionable plan.
The “to-be” map directly counters the problems found in the “as-is” analysis. Here are the key elements of a well-defined “to-be” state:
- Modular Architecture: The current monolithic system will be broken down into independent, single-purpose modules (e.g., PaymentService, InventoryUpdater). This is a fundamental shift from a tangled structure to an organized one.
- Transparent and Documented: The “black box” nature of the code will be eliminated. All public APIs and core business logic will be well-documented, making the code predictable and easy for new developers to understand.
- Robustness and Reliability: The new system will have clear, graceful error handling and comprehensive automated tests for all business rules. This ensures the system can handle edge cases and failures without crashing, building confidence in the codebase.
- Improved Performance and Scalability: By optimizing the code and removing inefficiencies, the new system will have consistent, low latency and the ability to handle future growth in user traffic without performance degradation.
- Preserved Identity: Although the internal workings are entirely new, the system’s core identity remains the same. It will continue to take the same inputs and produce the same outputs, ensuring no disruption to the larger application.
This defined “to-be” state is your guiding principle. It gives you a clear finish line, allowing you to make consistent decisions, measure your progress, and know exactly when the refactoring journey is complete.
Begin With the End in Mind
Before picking up the hammer, you need a blueprint. As the Persian poet Rumi wrote:
“First you must cast a glance, then take a step , for without a glance, you cannot take a step.”
I’m not sure about the translation, but here is the original:
نظر باید فکند آنگه قدم زد
که نتوان بی نظر در ره قدم زد
–عطار نیشابوری
In software, this means defining the ideal end state of your codebase before starting any refactor.
What does this look like?
- Clear architecture: modular components with well-defined responsibilities.
- Public APIs that express intent clearly.
- Code that is easy to read, test, and maintain.
The core principle of the Backward Refactoring is that we start the journey from the end by implementing the end desired goal. You don’t just think about what you want to achieve; you actively write the code you would write if the system were already clean and modular. This is the ultimate form of top-down design.
After writing this “ideal” code, you try to compile, build, and run your tests. Boom! You are met with a cascade of errors. And this is exactly what you want. Congratulations! Step one is done. These compiler errors are not failures; they are crucial informations. They are the guideposts that tell you precisely what’s missing in your existing codebase.
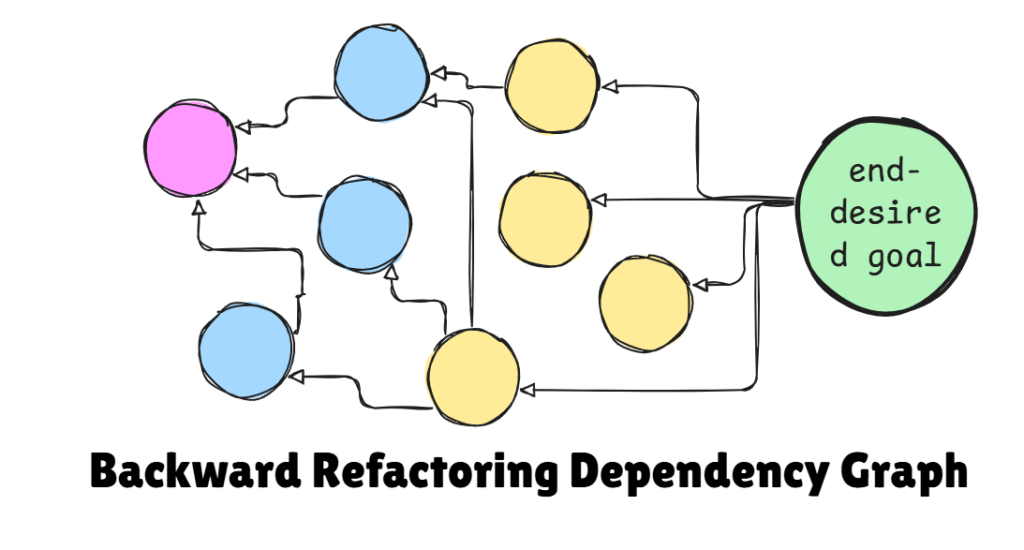
This is the moment to map the refactoring tree, which visualizes a dependency graph that charts every single error, from the top-level missing classes down to the smallest required methods. This top-down vision becomes your North Star, turning an overwhelming refactoring journey into a series of manageable, concrete steps.In Part 2, I’ll delve into the whole process in detail, providing a concrete, step-by-step guide to tackling big code refactoring safely and efficiently.
Introducing the Backward Refactoring
In the next part, I’ll introduce it in detail. But in summary, with Backward Refactoring, we start by drawing the Identity Matrix, that captures the “as-is” and “to-be” part of the journey you’re going to path. As its name goes, we start from the end desired goal of the refactoring, the number 10th of the matrix. In short, we do the following:
Here’s how the pattern works in practice:
- Write a test that precisely captures and asserts the end desired goal, we’re expecting from the code: First, we transform the end desired goal(“to-be” part of the refactoring) into a text against the code, we wish to surge it in the next few hours/days. This is the foundational step of the entire approach, creating a tangible representation of your ideal future state.
- Write the ideal code first, ignoring the current legacy code. This is where you fully manifest your “to-be” vision. Instead of getting bogged down in the mess of existing code, you write the new classes, methods, and APIs you wish the system already had. This isn’t just a mental exercise; it’s a concrete blueprint for the changes to come.
- Try to compile or run this ideal code. The compiler will generate errors, “missing classes” “undefined methods” “type mismatches.” These errors are not a sign of failure; they are your most valuable guideposts. Each error is a clear signal that the legacy code needs a specific change to meet your new design.
- Treat these compiler errors as signposts. Each error points to a part of the existing code that needs refactoring. They reveal the specific, measurable steps required to bridge the gap between your ideal design and the current reality. They remove the guesswork from the process, providing a precise roadmap.
- Draw a dependency graph of these errors, with the final ideal code as the root. This “refactoring tree” shows all the steps needed, from the smallest changes (the leaves) to the big-picture goal (the root). By visualizing these dependencies, you can strategically plan your work and identify the most efficient path forward.
- Start from the leaves, the smallest, easiest fixes. Work upwards incrementally, making small isolated changes that get you closer to compiling the ideal code. This approach minimizes risk and allows you to build momentum with a series of small, successful steps, rather than one massive, daunting task.
- Keep your tests as a safety net throughout to catch regressions. Your test suite is the single most important tool in this process. It acts as a continuous safety check, ensuring that as you make small changes, you aren’t accidentally breaking any existing functionality.
It is like solving a puzzle by starting with the finished picture and working backward from the edges, slowly connecting pieces until the full picture emerges. It turns an overwhelming project into a clear, step-by-step journey, turning an impossible task into a series of achievable goals.
Example: Refactoring the OrderProcessor
Let’s apply this to the e-commerce OrderProcessor you’ve been mapping.
Imagine the current code is a single, massive function called handleOrder(). It’s a classic “God function” that does everything: it validates the user, checks inventory, processes payment, and sends a shipping request, all in one place. Your goal is to break this monolith into a clean, modular system.
1. Define the End State
You start by writing the ideal code you wish you had. This code represents your “to-be” vision, where the responsibilities are clearly separated. You would write something like this:
newOrder().validateOrder().processPayment().requestShipping()
This simple chain of commands represents the clean, logical flow you want. The problem is, this code will immediately fail because your system doesn’t have these functions yet.
2. Let the Errors Be Your Guide
Each error you get is a clear signpost pointing to a specific part of the legacy code that needs to be refactored. The compiler will tell you:
- ‘newOrder’ not found
- ‘validateOrder’ not found
- ‘processPayment’ not found
These are not roadblocks; they are your to-do list.
3. The Incremental Journey
You don’t try to fix everything at once. You start from the leaves, the simplest, most independent task, and work your way up.
- Step 1: You decide to start with validateOrder(). You create a new function called validateOrder and move all the validation logic from the old handleOrder function into it.
- Step 2: Now, you call your new function from within your ideal code. The compiler has one less error. You still have many more, but you have made a small, successful step.
- Step 3: You repeat the process for processPayment(), then requestShipping().
Each small step brings you closer to your ideal. Gradually, the old, monolithic handleOrder function shrinks, and your new, clean architecture comes to life. The whole time, your test suite acts as a safety net, ensuring you don’t break anything.
Leave a Reply